APPLIES TO : Oracle SPARC Solaris ISSUE : Process Accounting Files (/var/adm/pacct) files are growing in size and in count as well, there is not proper log rotation in place GOAL :Rotate the /var/adm/pacct file and leave only 15 days file in server, delete the old file by having log rotation in place SOLUTION : /usr/lib/acct/turnacct script is used to manage the process accounting files in solaris servers, Modify the file based on our requirement and place enable it in daily cron job Prerequisites : NIL 1. Edit the script /usr/lib/acct/turnacct and comment the below line and add the next line root@JUDI-DEV-10:/root # vi /usr/lib/acct/turnacct #pfexec /usr/sbin/logadm -p now /var/adm/pacct pfexec /usr/sbin/logadm -C 15 -p now /var/adm/pacct
-C 15 - is to have only the last 15 files in server at any point in time
2. Now place the script in cron root@JUDI-DEV-10:/root # crontba -e 0 0 * * * /usr/lib/acct/turnacct switch >/dev/null 2>/dev/null 3. Now place the script in cron root@JUDI-DEV-10:/root # crontba -e
0 0 * * * /usr/lib/acct/turnacct switch >/dev/null 2>/dev/null This will rotate the pacct files daily and delete the old files from server which is older than 15. days.
APPLIES TO : Oracle SPARC Solaris ISSUE : A directory contains a huge amount of data, due to disk space constrain we need to convert that data into zfs volume. The challenge is how to retain the file ownership, permission, and soft/hard links GOAL :Create a zfs volume and move the local data with exact permission, ownership. SOLUTION : There isn't a built-in or automated way to create a new DataSet and migrate existing data to it. To get it done you'll need to create the dataset and manually (e.g. rsync) the data to it. Prerequisites : NIL 1. Move the data directory into a new name. root@JUDI-DEV-10:/root # mv /oracle /oracle_org 2. Create a zpool volume with a the new disk root@JUDI-DEV-10:/root # zpool create -f -m /oracle oracle c1d1 3. Copy the data to the zfs volume using the rsync command root@JUDI-DEV-10:/root # rsync -aAX /oracle_org/ /oracle 4. Verify the permission and ownership once the copy completed root@JUDI-DEV-10:/root # ls -rlt create zpool with existing data directory create zpool and sync with existing directory zfs create dataset from existing directory create zpool on existing directory with data Proper way to create a zfs off an existing directory ZFS: adding filesystem over existing directory create ZFS dataset over existing data converting existing directory to zfs dataset Zfs create dataset from existing directory
Migration Complete – Amazon’s Consumer Business Just Turned off its Final Oracle Database
Over my 17 years at Amazon, I have seen that my colleagues on the engineering team are never content to leave good-enough alone. They routinely re-evaluate every internal system to make sure that it is as scalable, efficient, performant, and secure as possible. When they find an avenue for improvement, they will use what they have learned to thoroughly modernize our architectures and implementations, often going so far as to rip apart existing systems and rebuild them from the ground up if necessary.
Today I would like to tell you about an internal database migration effort of this type that just wrapped up after several years of work. Over the years we realized that we were spending too much time managing and scaling thousands of legacy Oracle databases. Instead of focusing on high-value differentiated work, our database administrators (DBAs) spent a lot of time simply keeping the lights on while transaction rates climbed and the overall amount of stored data mounted. This included time spent dealing with complex & inefficient hardware provisioning, license management, and many other issues that are now best handled by modern, managed database services.
More than 100 teams in Amazon’s Consumer business participated in the migration effort. This includes well-known customer-facing brands and sites such as Alexa, Amazon Prime, Amazon Prime Video, Amazon Fresh, Kindle, Amazon Music, Audible, Shopbop, Twitch, and Zappos, as well as internal teams such as AdTech, Amazon Fulfillment Technology, Consumer Payments, Customer Returns, Catalog Systems, Deliver Experience, Digital Devices, External Payments, Finance, InfoSec, Marketplace, Ordering, and Retail Systems.
Migration Complete
I am happy to report that this database migration effort is now complete. Amazon’s Consumer business just turned off its final Oracle database (some third-party applications are tightly bound to Oracle and were not migrated).
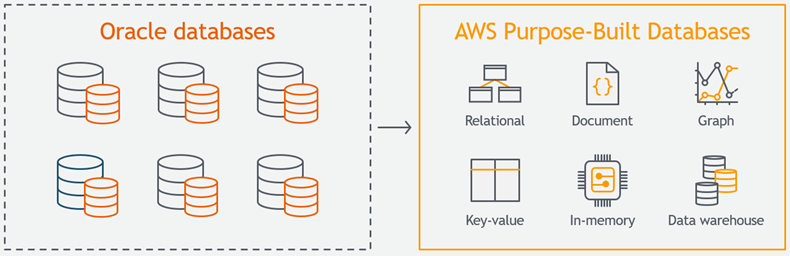
We migrated 75 petabytes of internal data stored in nearly 7,500 Oracle databases to multiple AWS database services including Amazon DynamoDB, Amazon Aurora, Amazon Relational Database Service (RDS), and Amazon Redshift. The migrations were accomplished with little or no downtime, and covered 100% of our proprietary systems. This includes complex purchasing, catalog management, order fulfillment, accounting, and video streaming workloads. We kept careful track of the costs and the performance, and realized the following results:
Cost Reduction – We reduced our database costs by over 60% on top of the heavily discounted rate we negotiated based on our scale. Customers regularly report cost savings of 90% by switching from Oracle to AWS.
Performance Improvements – Latency of our consumer-facing applications was reduced by 40%.
Administrative Overhead – The switch to managed services reduced database admin overhead by 70%.
The migration gave each internal team the freedom to choose the purpose-built AWS database service that best fit their needs, and also gave them better control over their budget and their cost model. Low-latency services were migrated to DynamoDB and other highly scalable non-relational databases such as Amazon ElastiCache. Transactional relational workloads with high data consistency requirements were moved to Aurora and RDS; analytics workloads were migrated to Redshift, our cloud data warehouse.
We captured the shutdown of the final Oracle database, and had a quick celebration:
DBA Career Path
As I explained earlier, our DBAs once spent a lot of time managing and scaling our legacy Oracle databases. The migration freed up time that our DBAs now use to do an even better job of performance monitoring and query optimization, all with the goal of letting them deliver a better customer experience.
As part of the migration, we also worked to create a fresh career path for our Oracle DBAs, training them to become database migration specialists and advisors. This training includes education on AWS database technologies, cloud-based architecture, cloud security, OpEx-style cost management. They now work with both internal and external customers in an advisory role, where they have an opportunity to share their first-hand experience with large-scale migration of mission-critical databases.
Migration Examples
Here are examples drawn from a few of the migrations:
Advertising – After the migration, this team was able to double their database fleet size (and their throughput) in minutes to accommodate peak traffic, courtesy of RDS. This scale-up effort would have taken months.
Buyer Fraud – This team moved 40 TB of data with just one hour of downtime, and realized the same or better performance at half the cost, powered by Amazon Aurora.
Financial Ledger – This team moved 120 TB of data, reduced latency by 40%, cut costs by 70%, and cut overhead by the same 70%, all powered by DynamoDB.
Wallet – This team migrated more than 10 billion records to DynamoDB, reducing latency by 50% and operational costs by 90% in the process. To learn more about this migration, read Amazon Wallet Scales Using Amazon DynamoDB.
My recent Prime Day 2019 post contains more examples of the extreme scale and performance that are possible with AWS.
Migration Resources
If you are ready to migrate from Oracle (or another hand-managed legacy database) to one or more AWS database services, here are some resources to get you started:
AWS Migration Partners – Our slate of AWS Migration Partners have the experience, expertise, and tools to help you to understand, plan, and execute a database migration.
AWS Database Freedom – The AWS Database Freedom program is designed to help qualified customers migrate from traditional databases to cloud-native AWS databases.
AWS re:Invent Sessions – We are finalizing an extensive lineup of chalk talks and breakout sessions for AWS re:Invent that will focus on this migration effort, all led by the team members that planned and executed the migrations.
APPLIES TO : Oracle SPARC Solaris ISSUE : The pool is formatted using an older on-disk format. The pool can still be used, but some features are unavailable. GOAL :Upgrading ZFS Storage Pools in Solaris 11.4 SOLUTION : Upgrade the zpool to latest version to avail all the features. Prerequisites : 1. Check the zpool status to find the version. root@JUDI-DEV-10:/root# zpool status pool: rpool state: ONLINE status: The pool is formatted using an older on-disk format. The pool can still be used, but some features are unavailable. action: Upgrade the pool using 'zpool upgrade'. Once this is done, the pool will no longer be accessible on older software versions. config: NAME STATE READ WRITE CKSUM rpool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 c0t6000CCA02A507030d0 ONLINE 0 0 0 c0t6000CCA02A507984d0 ONLINE 0 0 0 errors: No known data errors root@JUDI-DEV-10:/root#
2. Check the servers zpool software installed version and zpool volume is configured in which version. root@JUDI-DEV-10:/root# zpool upgrade This system is currently running ZFS pool version 45. The following pools are out of date, and can be upgraded. After being upgraded, these pools will no longer be accessible by older software versions. VER POOL --- ------------ 44 rpool Use 'zpool upgrade -v' for a list of available versions and their associated features. root@JUDI-DEV-10:/root# The Installed version of zpool version in OS is 45, The rpool volume is with version 44 3. List of available versions and their associated features.. root@JUDI-DEV-10:/root# zpool upgrade -v This system is currently running ZFS pool version 45. The following versions are supported: VER DESCRIPTION --- -------------------------------------------------------- 1 Initial ZFS version 2 Ditto blocks (replicated metadata) 3 Hot spares and double parity RAID-Z 4 zpool history 5 Compression using the gzip algorithm 6 bootfs pool property 7 Separate intent log devices 8 Delegated administration 9 refquota and refreservation properties 10 Cache devices 11 Improved scrub performance 12 Snapshot properties 13 snapused property 14 passthrough-x aclinherit 15 user/group space accounting 16 stmf property support 17 Triple-parity RAID-Z 18 Snapshot user holds 19 Log device removal 20 Compression using zle (zero-length encoding) 21 Deduplication 22 Received properties 23 Slim ZIL 24 System attributes 25 Improved scrub stats 26 Improved snapshot deletion performance 27 Improved snapshot creation performance 28 Multiple vdev replacements 29 RAID-Z/mirror hybrid allocator 30 Encryption 31 Improved 'zfs list' performance 32 One MB blocksize 33 Improved share support 34 Sharing with inheritance 35 Sequential resilver 36 Efficient log block allocation 37 LZ4 compression 38 Xcopy with encryption 39 Resilver restart enhancements 40 New deduplication support 41 Asynchronous dataset destroy 42 Reguid: ability to change the pool guid 43 RAID-Z improvements and cloud device support 44 Device removal 45 Lazy deadlists For more information on a particular version, including supported releases,see the ZFS Administration Guide. root@JUDI-DEV-10:/root#
4. Upgrade the zpool version from 44 to 45 (The latest zpool version) root@JUDI-DEV-10:/root# zpool upgrade rpool This system is currently running ZFS pool version 45. Successfully upgraded 'rpool' from version 44 to version 45 root@JUDI-DEV-10:/root# 5. Check the status of zpool version root@JUDI-DEV-10:/root# zpool upgrade This system is currently running ZFS pool version 45. All pools are formatted using this version. root@JUDI-DEV-10:/root#